笔记:Domain-specific languages for the automated generation of datasets for industry 4.0 applications
Domain-specific languages for the automated generation of datasets for industry 4.0 applications
作者来自西班牙坎布里亚大学
Abstraction
Data collected in Industry 4.0 applications must be converted into tabular datasets before they can be processed by analysis algorithms, as in any data analysis system. To perform this transformation, data scientists have to write complex and long scripts, which can be a cumbersome process. To overcome this limitation, a language called Lavoisier was recently created to facilitate the creation of datasets. This language provides high-level primitives to select data from an object-oriented data model describing data available in a context. However, industrial engineers might not be used to deal with this kind of model. So, this work introduces a new set of languages that adapt Lavoisier to work with fishbone diagrams, which might be more suitable in industrial settings. These new languages keep the benefits of Lavoisier, reducing dataset creation complexity by 40% and up to 80%, and outperforming Lavoisier in some cases.
Introduction
本文重点关注那些旨在利用构成现代装配线的不同互连元素收集的大量数据的工业4.0应用。MES (Manufacturing Execution System)。然后可以对这些大量数据进行分析,以改进制造过程及其输出产品。Zero-Defect Manufacturing (ZDM) 。
数据集是一种基于表的格式,与所分析的每个元素相关联的所有数据必须放在该表的一行中。然而,这种格式的数据并不常见,因为它通常存储在关系数据库、XML或JSON文件中。在这些表示中,数据不是表格式的,而是链接的,通常是分层的。例如,关于制造产品的数据可以链接到其组件的数据。类似地,每个组件的数据可能连接到其子组件的数据,依此类推。因此,在将这些分层数据用作数据分析算法的输入之前,我们需要将它们扁平化,以便将它们排列成表中特定行的列。
为了执行平坦化任务,数据科学家通常用SQL、R或Pandas等语言编写复杂而冗长的脚本。为了缓解这些问题,一种叫做Lavoisier的语言最近被开发出来[52]。这种语言提供了高级原语来创建数据集,这些数据集关注于必须选择哪些数据,而忽略了必须如何重新排列这些数据以使它们适合数据集的细节。
另一方面,工业工程师被用来处理鱼骨图,它允许表示因果关系,通常用于工业环境中的质量控制,并且可以用于指定领域数据之间的影响关系。因此,在工业4.0上下文中,更希望Lavoisier能够使用鱼骨图而不是面向对象的领域模型。
这项工作提出了一个模型驱动的过程,使Lavoisier适应于使用鱼骨图。为了构建这个过程,我们首先创建了一种新的鱼骨模型,称为面向数据的鱼骨模型,其中原因可以连接到领域数据。为此,我们用Lavoisier语句增强鱼骨模型,这样每个原因都可以连接到表征这种原因的领域数据子集。接下来,我们设计了一种名为Papin的新语言来选择应该使用鱼骨图的哪些原因来构建具体的数据集。最后,Papin解释器处理这个选择并自动生成所需的数据集。因此,工业工程师可以使用Papin直接从(面向数据的)鱼骨图创建数据集,而不是从面向对象的领域模型。
通过将面向数据的鱼骨模型和Papin语言应用于五个外部案例研究,评估了这些语言的表达能力。
这项工作扩展了以前在一次会议上提出的贡献在这一贡献中,作为主要区别,本文包括了对我们方法的表达性和有效性的更详尽的评估(第5节),以及对所呈现语言如何实现的更详细的描述(第4节)。此外,我们扩展了相关工作部分,包括propositionalization和Multi-Relational Data Mining (MRDM)以及工业4.0和ETL过程中的建模语言。
Background and motivation
Software language engineering via metamodelling
DSL语言比General Purpose Language (GPL)的强制性更低。DSL允许使用包含来自应用领域的术语和自定义语法。介绍元模型技术。
Running example: Falling band
作为贯穿本文的运行示例,我们将以一家汽车行业供应商公司的驱动半轴生产为例。在这些检查中,汽车制造商发现,有时车轮一侧的箍松开,引起不同的问题。该公司希望分析在驱动半轴生产过程中收集的数据,以找到这个问题的原因。
Data mining processes
KDD(Knowledge Discovery in Databases) [65] 我们将以KDD过程为基础,解释作为数据挖掘过程一部分的不同阶段。绘制了一个流程图介绍KDD过程,分别是bussis questions, data sources selection, domain data model, algorithm selection, data reshaping, data preparation, algorithm execution, results reports。
The dataset generation problem
关注其中的data reshaping问题。大多数数据分析算法只能处理以具体表格格式提供的数据,在数据科学社区中称为数据集。在这种格式中,属于要分析的单个实体的所有数据必须放在同一个表行中,我们将其命名为一个实体,一行约束。然而,域数据通常以链接和嵌套元素的图的形式提供,如JSON等。为了创建数据集,数据科学家编写复杂而冗长的脚本,其中使用不同的低级操作链(如过滤器、连接、pivot或聚合)转换原始数据,以满足一个实体、一行约束。
读者可以很容易地注意到,与示例大小相比,这个脚本相当复杂,并且如果紧缩的数量增加,它有明显的可伸缩性问题。这个问题并不是SQL语言所特有的,在使用R或Pandas等其他替代语言时也会出现类似的情况。因此,数据集创建成为一个劳动密集型且容易出错的过程。
Lavoisier
为了克服这个问题,最近发展了一种叫做Lavoisier[52] [71] 的语言。Lavoisier是一种用于数据集创建的声明性语言,它提供了一组高级原语,其目标是指定数据集中必须包含哪些数据,而不必详细说明所选数据必须如何转换才能安排为数据集。
通过使用拉瓦锡,与用于此目的的其他语言(如SQL或Pandas)相比,生成数据集所需的操作总数减少了~ 40%,脚本大小减少了~ 60%。因此,作为一个初步假设,我们认为拉瓦锡可能有助于工业4.0的数据选择。然而,我们很快意识到,我们所在地区公司的大多数工业工程师并不熟悉面向对象的数据模型,也不熟悉一般的数据模型。
因此,我们分析了这些公司中通常使用的模型类型,以及这些模型是否可以用作我们方法中面向对象数据模型的替代品。在几个备选方案中,例如描述装配线的图,我们发现了一种模型类型,称为鱼骨图,它为我们的目标提供了三个有趣的元素:(1)它为相当数量的工程师所知;(2)它有一个非常容易理解的符号;(3)可用于表示域数据之间的因果关系。因此,当我们在工业4.0环境中工作时,我们决定使用这些鱼骨图来取代我们原始解决方案的面向对象数据模型。
Fishbone diagrams
结合案例介绍了鱼骨图的基本概念。
Problem statement
Lavoisier是面向对象的,鱼骨图是面向数据的,需要进行一个结合。
Dataset generation from fishbone diagrams
Solution overview
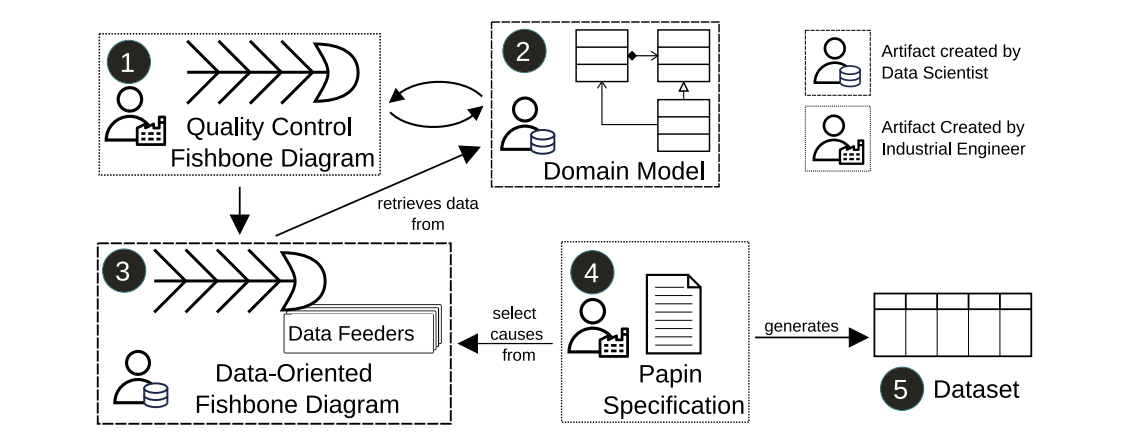
工业工程师先创建鱼骨图,数据工程师创建面向对象领域模型,并鼓励彼此检查。数据工程师创建Data-Oriented Fishbone diagram(DOF) DOF重塑了质量控制鱼骨图,并将原因与表征这些原因的数据联系起来。原因和领域数据之间的连接是使用我们称为data feeders的特殊代码块建立的。最后,工业工程师会使用名为Papin的语言制作数据集。
Data-oriented fishbone models
DOF将原鱼骨图和面向对象的数据连接起来,连接器是data feeder,它由path和Lavoisier Expression组成。后文介绍了DOF的代码含义和作用。
Papin: Dataset specification by cause selection
在建立DOF后,我们使用Papin来指定该模型的原因,该模型应该包含在用于分析DOF效应的数据集中。
Papin规范的解释程序:
- 对于Papin规范选择的每个类别或原因,我们遍历它以提取其数据链接的原因。
- 每个数据链接的原因都使用Lavoisier解释器求值,它为每个原因返回一个数据集。
- 所有这些数据集都使用主类的标识符作为数据集行之间的匹配属性进行合并。
- 结果数据集被写入CSV文件。
Implementation
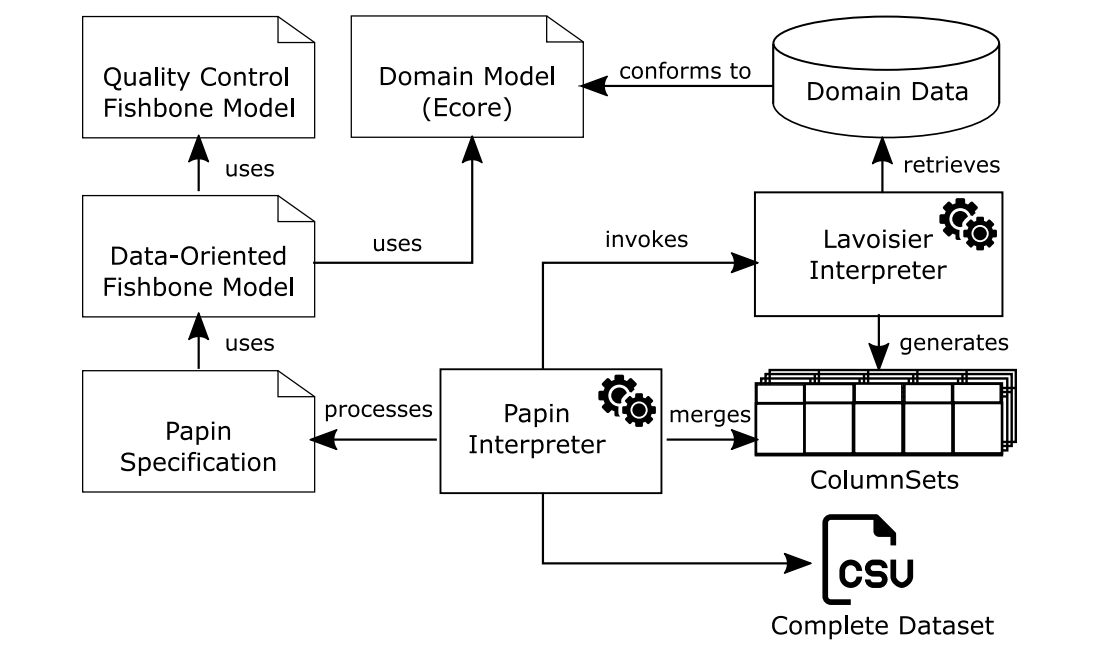
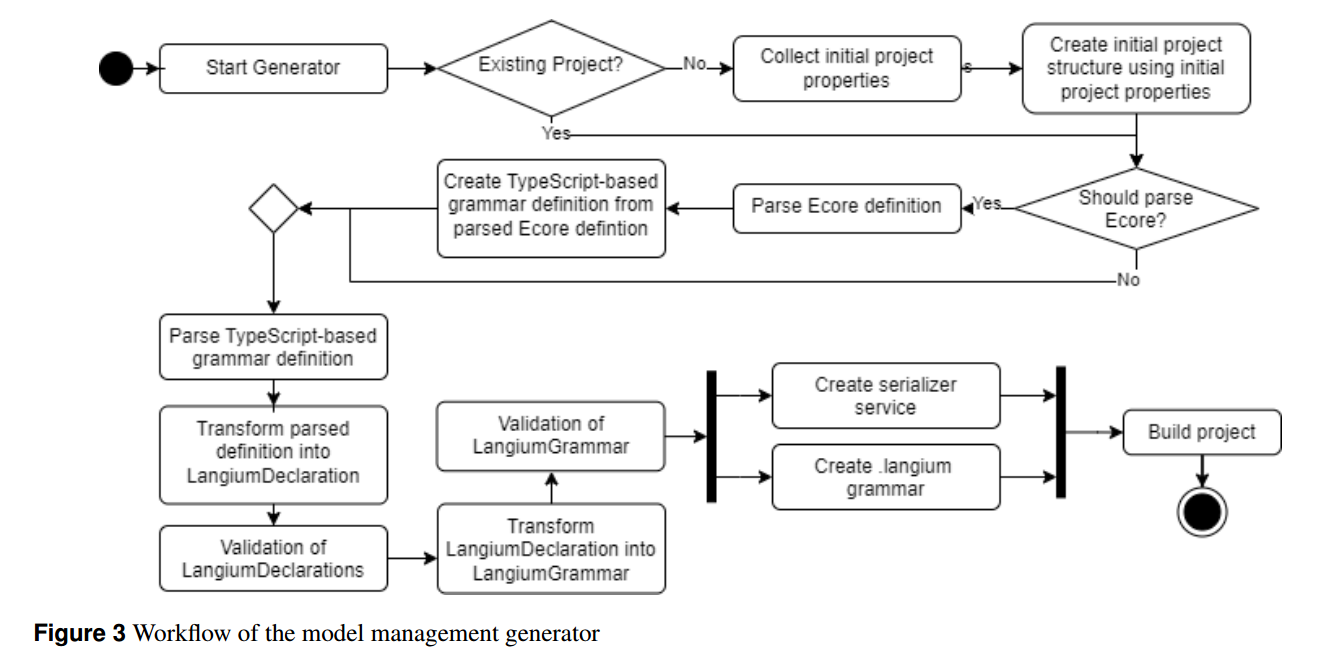
图8提供了组成模型驱动的基础结构的不同元素的方案。该基础设施包括:
- 我们为三种特定于领域的语言提供了相应的编辑器和解析器;
- 使用Ecore指定的面向对象领域模型;
- 通过领域模型检索的领域数据,因此必须符合该模型;
- Papin解释器,它生成包含所需输出数据集的CSV文件;
- Lavoisier解释器,它由Papin解释器调用来处理data feeder的Lavoisier表达式。
模型驱动工具的结构介绍。其中DOF工具的语法是用Xtext创建的。
Evaluation
这些语言有两个主要目标:(1)提高在创建数据集时执行工作的抽象级别;(2)避免业内人士不得不处理他们不熟悉的模型格式来创建数据集。
我们通过分析三个不同的因素来验证这些目标是否已经实现:(1)语言表达性,也就是说,所创建的语言是否可以有效地用于不同的工业4.0问题;(2)工业工程师能否有效处理Papin规范;(3)使用dof和Papin生成数据集可以节省多少意外复杂度。
下面,我们首先描述对语言表现力的评价。然后,我们描述了一个小实验,我们进行了检查工业工程师是否能够理解和创建Papin规范,我们分析了它的结果。接下来,我们将详细介绍我们所遵循的过程,以评估由于dof和Papin可以消除多少意外复杂性,并讨论执行该过程后收集的结果。最后,我们评论和分析了对我们的结果有效性的潜在威胁。
Expressiveness
结合了汽车行业的五个案例,列出了模型数量和鱼骨图数量。证明鱼骨图的表达能力是足够的,也介绍了三个和语法无关的问题。
Experiments with industrial engineers
这些经验实验是评估使用DSL的好处的最有效方法之一[79] [80]。然而,不幸的是,这些类型的实验在DSL和工业4.0社区中都非常罕见。这些实验的主要问题,也可能是它们在社区中不常见的原因,是它们的设计、组织和执行需要在时间和资源方面付出巨大的努力,这通常超出了常规研究项目的限制。由于这些原因,我们选择了一个更简单的程序,即向一组工业工程师分发一份在线问卷,他们必须解决一些与Papin相关的练习。给他们发放答卷让他们作答,问题基本都超过8成人答对。有一些初步证据表明工业工程师能够有效地使用Papin。
Accidental complexity reduction
Evaluation procedure
展示了通过使用面向数据的鱼骨模型和Papin进行数据选择和准备来衡量可以节省多少意外复杂性的努力。(1)要包含在比较中的技术(为什么选这个技术);(2)待计算度量的集合(为什么这样度量);(3)用每种语言编写脚本的场景。评估的过程不多介绍。
Evaluation results
放弃了自由度选项,因为添加可追溯性信息显然是昂贵的。
脚本大小。1. 除了Data Feeders选项中的场景a和b之外,我们的方法比SQL和Pandas执行得更好。2. Data Feeders选项总是比Lavoisier选项差。3. 在所有情况下,Just Papin选项明显优于拉瓦锡选项,除了a。4. “Just Papin”选项的大小似乎并不取决于场景的复杂程度。……这段讨论非常长,总体上就是在讨论谁好谁坏的问题。
Threats to validity
Expressiveness - 2
语言表达性是软件语言工程中的常见问题。然而,虽然这种威胁不能完全消除,但我们已经尝试通过使用与实际工业问题相对应的外部和异构案例研究来减轻它,以便这些案例研究:(1)涵盖广泛的可能情况;(2)对我们没有偏见;(3)代表真实的工业问题,而不是在研究实验室中人为制造的玩具例子。关于这最后一点,我们想指出的是,虽然这四个案例研究是从文献中得出的,但它们对应的是不同现实公司面临的问题。另一方面,完全可以认为鱼骨图是由案例研究提供的,但是领域模型是由我们创建的,因此,这些领域模型可能是有偏差的。正如2.7节所述,领域模型在工业环境中很少使用,因此在实践中寻找对应于实际工业问题的案例研究,同时提供鱼骨图和领域模型是一项不可行的任务。因此,我们决定为每个案例研究创建领域模型,只使用相应案例研究中报告的可用数据的描述。此外,为了减少潜在的偏差,我们请了几位专家和实践者来检查我们创建的领域模型。没有人报告这些型号有任何问题。
Experiments with industrial engineers - 2
关于测试工业工程师是否能够使用Papin的实验,我们对这些实验使用了单个案例研究。因此,为了科学严谨,我们不能将这些实验的结论推广到其他案例研究中,因为我们没有证据表明工业工程师可以将Papin用于其他案例研究。尽管如此,这个案例研究取自一个真实的案例研究,它不是一个微不足道的案例,它具有在真实场景中预期的复杂程度。因此,没有任何特殊性会让我们认为工程师在其他案例研究中使用Papin会有问题。
其次,我们无法控制受访者如何回答问题。其次,我们无法控制受访者如何回答问题。更严重的威胁是,我们在训练和练习中使用了相同的案例研究。
Accidental complexity reduction - 2
意外复杂性降低的结果是我们为比较设计的场景的结果,但其他场景可能会产生不同的结果。……
Related work
Fishbone diagrams and data models
该部分报告了一些使用鱼骨图进行需求工程或者模型驱动工程之类建模的案例。
Azzoni等人[92]已经发布了一个将CSV文件转换为Ecore模型的工具,以便这些元素之间的关系可以更容易地可视化。该工具将一组CSV文件和Ecore中指定的域模型作为输入,并提供将CSV列映射到域模型元素的机制。使用此映射,该工具能够生成将CSV数据加载到Ecore域模型实例所需的代码。
最后,DescripML[93] [94] 是一种特定于领域的语言,用于描述数据集的内容。在这种情况下,数据集已经存在,该工具旨在提供一种通用语言来描述其内容,以便数据集的文档变得更加统一,并且可以更容易地检查和比较。此外,该语言还提供了一些功能,提醒数据科学家注意可能导致机器学习算法出现问题的问题,例如性别失衡的数据集。这种语言用于已经创建的数据集,而我们感兴趣的是自动生成这些数据集。
Models in Industry 4.0
参考的是论文[82]中有关工业4.0建模的分析。包括UML、SysML、OWL、AutomationML、EXPRESS、DSL等。这些语言用于不同的目的,从指定制造过程[114]到描述CAD(计算机辅助设计)应用程序的交换格式[115] [116]。在我们的例子中,我们对两种类型的语言感兴趣:(1)那些可以用来指定概念数据模型的语言;(2)工业工程师熟悉的语言,不直接关注数据表示,但可以以某种方式与数据相关联,从而用作数据选择的基础。
Languages for data modeling
分别介绍了UML、ER、EXPRESS等语言。
Well-known modeling languages in industry
介绍了SysML语言。
Dataset generation
propositionalization社区已经研究了从分层和嵌套数据生成数据集的问题。他们的目标是将复杂的数据图转换成表格结构,可以用作数据分析算法的输入。
Datasets and ETL processes
数据集创建可以被认为是ETL(Extract, Transform, Load)过程的一个特殊情况。在这些过程中,首先从一个或多个源提取数据,这些源可能采用不同的格式,然后根据需要对它们进行转换,最后将其加载到特定的结构中,在我们的示例中,该结构将是满足一个实体、一行约束的表格结构。然而,这个概念主要应用于数据仓库的构建,据我们所知,没有专门为数据集生成定义的ETL过程。结合了一些跟ETL过程有关的工作。
Summary and future work
本文描述了一组语言,用于为工业环境中的数据分析系统(如工业4.0应用程序)自动生成数据集。该过程采用了Lavoisier(一种用于自动生成数据集的语言)来处理鱼骨模型,而不是面向对象的数据模型。面向对象的数据模型很少被发现,但工业工程师习惯于处理鱼骨模型,因此我们认为这些模型比面向对象的模型更适合于制造环境。
为了使Lavoisier适应鱼骨模型,我们设计了两种新的语言。首先,我们创建了鱼骨模型的一个变体,称为面向数据的鱼骨模型,它可用于表示领域数据之间的影响关系。在这些模型中,原因通过称为数据馈线的特殊代码块连接到领域数据。通过这种方式,可以使用域数据来描述鱼骨模型中的原因,而鱼骨模型现在指定域数据之间的影响关系。数据馈送器的代码是基于Lavoisier的,它被设计为供没有数据科学专业知识的人使用。因此,数据馈送器甚至可以由工业工程师自己编写。然而,这一假设尚未得到实证验证。
其次,我们设计了第二种语言,称为Papin,用于选择要包含在数据集中的原因。这是一种非常简洁的语言,它只引用原因,从而使工业工程师不必处理面向对象的数据模型。Papin解释器处理这些规范,调用Lavoisier解释器来执行数据馈线,并自动生成所需的数据集。
第三,我们通过将这些语言应用于五个案例研究来评估它们的表达性,其中四个来自文献,其余一个来自工业合作伙伴。没有重大问题的报告。此外,我们评估了我们的方法是否保留了拉瓦锡在降低意外复杂性方面的优势。
结论是,我们的方法在降低意外复杂性方面优于SQL和Pandas。与拉瓦锡相比,我们的方法引入了与需要创建DOF相关的初始开销。另一方面,Papin是一种非常简单的语言,可以用很少的关键词选择大量的特征。
因此,当我们从领域模型生成少量数据集时,与DOF创建相关的初始努力可能不会得到回报,但是随着这个数量的增加,我们的方法开始提供好处。
总之,可以说我们的方法有助于减少创建数据集所需的意外复杂性,这将有助于减少开发时间,从而减少工业4.0应用程序的成本。此外,它可以帮助减轻对数据科学家的依赖,他们的费用通常很昂贵,而且可用性可能很少。数据科学家仍然需要构建面向对象的领域模型,但他们可能不需要构建dof和Papin规范。
作为未来的工作,我们计划进行更复杂的控制实验,这将使我们能够更好地测试工业工程师是否真的能够使用我们的语言。我们还将研究替代的具体语法是否可能比当前的文本语法更合适。例如,可以使用语言工作台(如Sirius)创建图形化的具体语法,使用提议语言的现有元模型作为抽象语法。或者,可以使用Picto等工具自动生成图形视图(即无编辑功能)来补充当前的文本语法。此外,我们将开发工具来从相应的QCF模型生成DOF的骨架,以帮助减少与构建DOF相关的工作量。我们将研究如何警告用户在创建数据集时可能出现的一些问题,例如合并两个列,它们之间存在功能依赖关系。我们还将尝试使拉瓦锡适应Ecore以外的数据建模语言,如EXPRESS或OWL。我们将探讨在工业环境中非常流行的其他建模语言,如SysML,是否可以代替鱼骨图作为数据选择的基础。最后,我们将在语言中添加支持,以便在数据馈送器中指定聚合值,这样,例如,表示集合平均值的列就可以包含在数据集中。
个人总结
这篇文章是基于Lavoisier语言的后续文章,大致可以理解为将数据集构建中数据结构搭建的部分工作进行了基于模型化,用更规范地流程减少了重复工作。工具链本身似乎不复杂,无非是对两个语言的介绍,文章后面实验部分的讨论非常冗长,思想可以借鉴但有用没用得太多。自称实用性很强但观感一般,文章写作质量一般。
参考文献
[52]A. de la Vega, D. García-Saiz, M. Zorrilla, P. Sánchez, Lavoisier: A dsl for increasing the level of abstraction of data selection and formatting in data mining, J. Comput. Lang. 60 (2020) 100987, http://dx.doi.org/10.1016/j.cola.2020.100987.
[65]U. Fayyad, G. Piatetsky-Shapiro, P. Smyth, From data mining to knowledge discovery in databases, AI Mag. 17 (1996) 37, http://dx.doi.org/10.1609/ AIMAG.V17I3.1230.
[71]A. de la Vega, Domain-Specific Languages for Data Mining Democratisation (Ph.D. thesis), Universidad de Cantabria, 2019, URL http://hdl.handle.net/ 10902/16728.
[79]T. Kosar, S. Gaberc, J.C. Carver, M. Mernik, Program comprehension of domainspecific and general-purpose languages: replication of a family of experiments using integrated development environments, Empir. Softw. Eng. 23 (5) (2018) 2734–2763, http://dx.doi.org/10.1007/s10664-017-9593-2.
[80]A. Barisic, V. Amaral, M. Goulão, Usability driven DSL development with USEME, Comput. Lang. Syst. Struct. 51 (2018) 118–157, http://dx.doi.org/10.1016/ j.cl.2017.06.005.
[92]I. Al-Azzoni, N. Petrovic, A. Alqahtani, A utility to transform CSV data into EMF, in: Proceedings of the 8th International Conference on Software Defined Systems (SDS), Gandía (Spain), 2021, pp. 1–6, http://dx.doi.org/10.1109/SDS54264.2021.9732143.
[93]J. Giner-Miguelez, A. Gómez, J. Cabot, A domain-specific language for describing machine learning datasets, J. Comput. Lang. 76 (2023) 101209, http: //dx.doi.org/10.1016/j.cola.2023.101209.
[94]J. Giner-Miguelez, A. Gómez, J. Cabot, DescribeML: A dataset description tool for machine learning, Sci. Comput. Program. 231 (2024) 103030, http: //dx.doi.org/10.1016/j.scico.2023.103030.
[82]A. Wortmann, O. Barais, B. Combemale, M. Wimmer, Modeling languages in Industry 4.0: an extended systematic mapping study, Softw. Syst. Model. 19 (1) (2020) 67–94, http://dx.doi.org/10.1007/s10270-019-00757-6.
[114]M. Schleipen, R. Drath, Three-view-concept for modeling process or manufacturing plants with automationml, in: Proceedings of the Conference on Emerging Technologies & Factory Automation, EFTA, Palma de Mallorca (Spain), 2009, pp. 1–4, http://dx.doi.org/10.1109/ETFA.2009.5347260.
[115]G.P. Gujarathi, Y. Ma, Parametric CAD/CAE integration using a common data model, J. Manuf. Syst. 30 (3) (2011) 118–132, http://dx.doi.org/10.1016/j.jmsy.2011.01.002.
[116]A. Perzylo, N. Somani, M. Rickert, A. Knoll, An ontology for CAD data and geometric constraints as a link between product models and semantic robot task descriptions, in: Proceedings of the International Conference on Intelligent Robots and Systems (IROS), Hamburg (Germany), 2015, pp. 4197–4203, http: //dx.doi.org/10.1109/IROS.2015.7353971.